
Solutions Consultant?
A little bit of everything, no specific classification
- DevOps: CI/CD (TeamCity!), Ansible, packaging
- Databases, SQL, ETL
- Windows Security / Kerberos / AD
- Front-end & UI
- Old protocols & platforms (AS/400, iSeries)
- Proprietary DBs (such as SQL Server 2012, Oracle 9, DB/2)
- Web servers / reverse proxies (Caddy, nginx)
- Whetever else arises... JDBC errors - TLS incompatibility - SSL certs
Alert: Live coding ahead


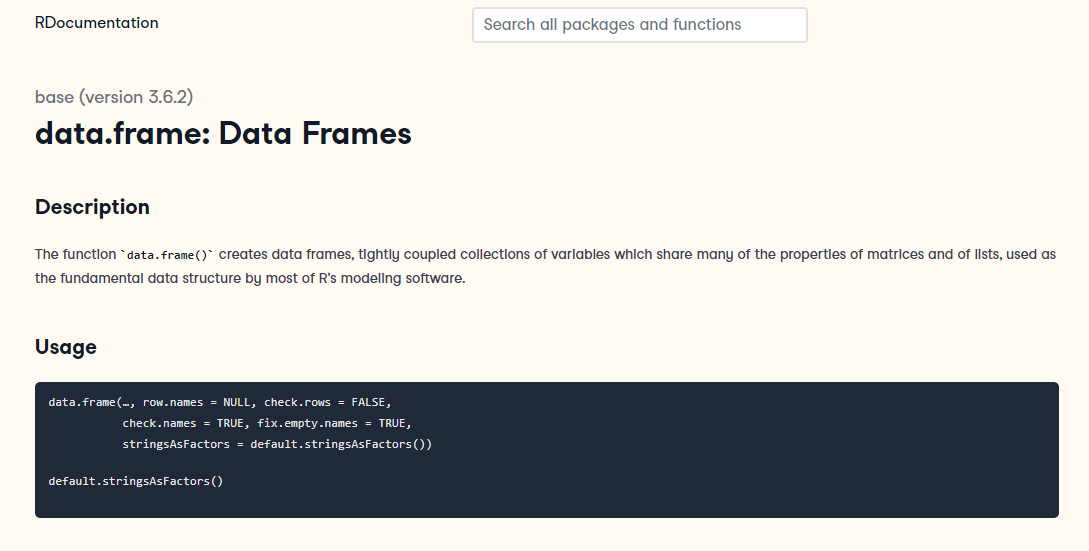
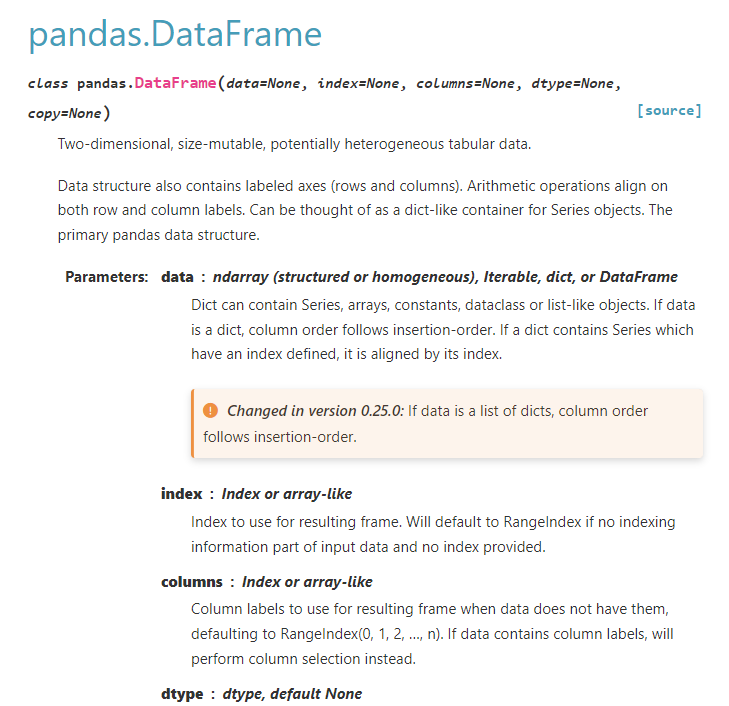
What is a dataframe?
Some esoteric, complex, binary data structure used in advanced ML research projects?

- No! A data frame is simply a tabular structure containing equally-sized columns of data.
- More simply, a “data table.”
Dataframe examples
Dataframes, or tables, are everywhere!
- Database tables & views
- Excel spreadsheets
- CSV files
- HTML tables
- BI reports
Because of their ubiquity, a powerful library to load, manipulate, calculate, transform and export data frames is the core component of any data ecosystem
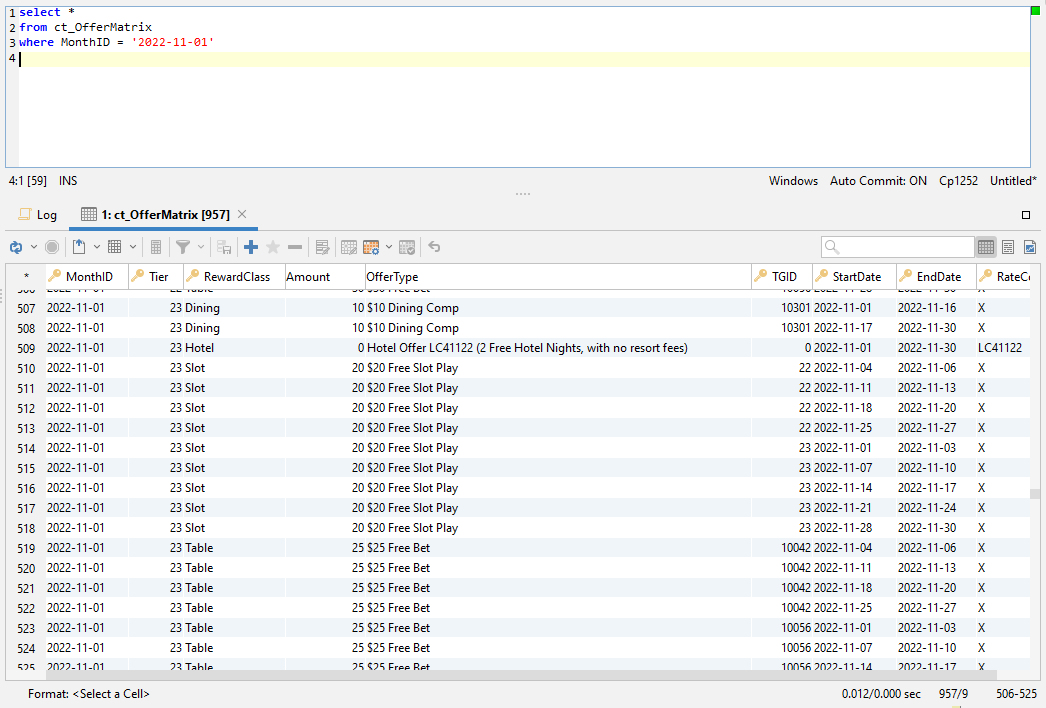
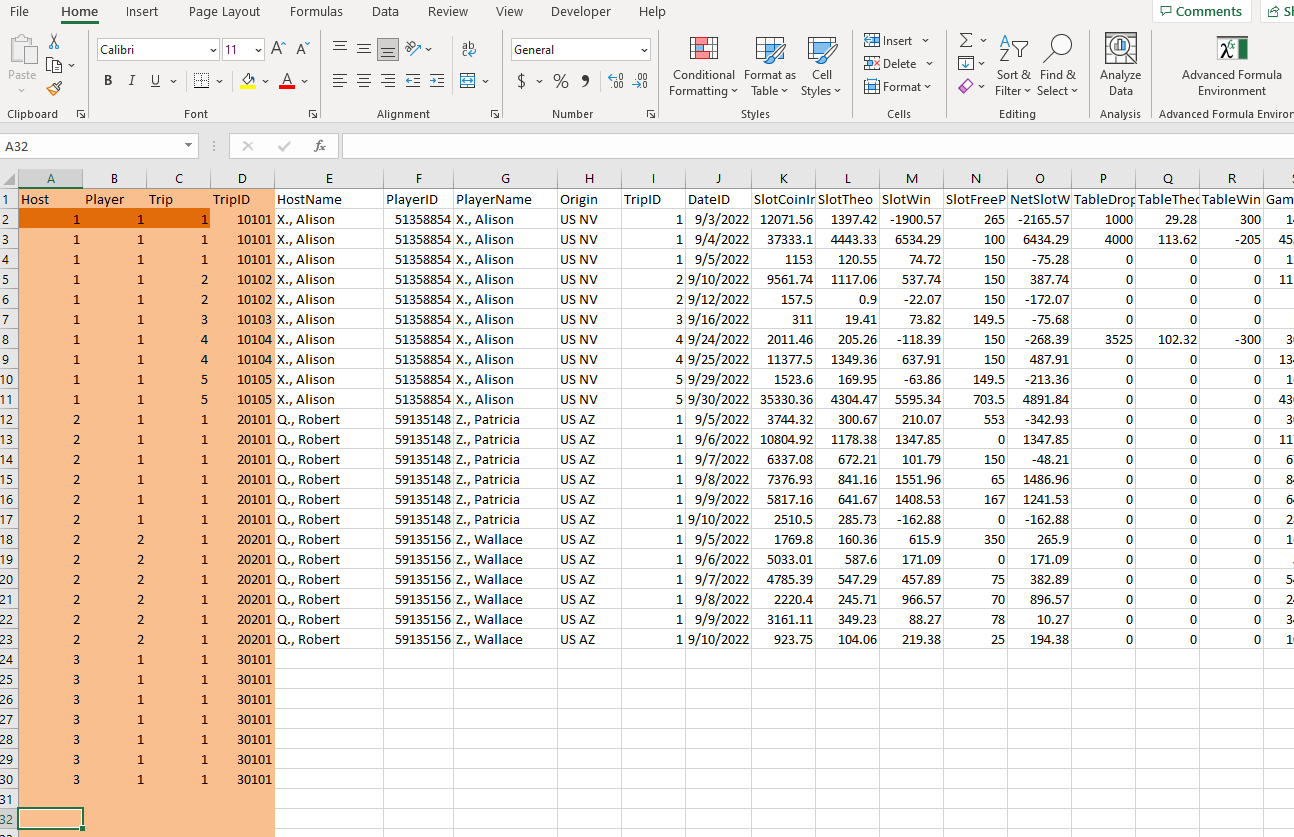
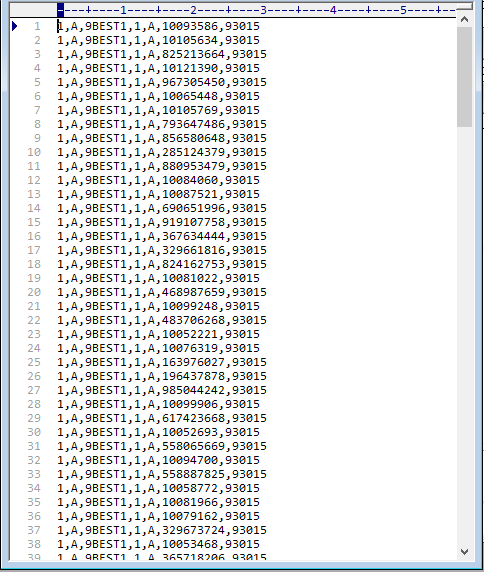
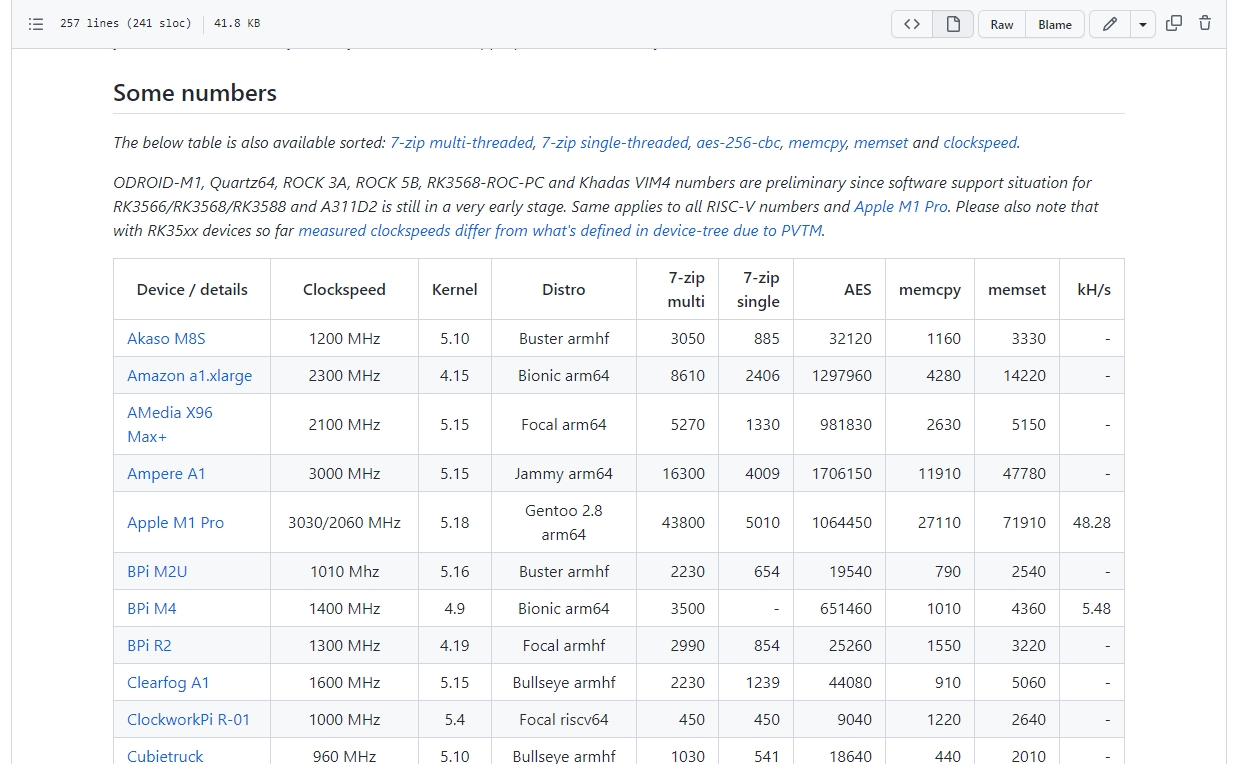

Evolution of dataframe libraries
Long history – not a Kotlin invention
- fundamental in R-lang
- Python "pandas"
- Julia dataframes.jl
- Apache Spark
At least 30+ years old



Problems, issues, concerns
Existing implementations are far from perfect
- R, Python, Julia are all dynamically-typed languages
- they support type hints, but not enforcable types
- difficult APIs, some very ugly syntax
- dplyr is an updated data analysis framework for R, basically a new language, because base-R is quite difficult
- complaints about pandas are all over the web: for example on Hacker News
- even pandas's creator is mixed
- Apache Arrow and the "10 Things I Hate About pandas" by Wes McKinney
- forced indexes are often redundant, and make easy things difficult
Kotlin perspective
What can a Kotlin version improve upon?
- Fully chainable methods
- build code blocks without intermediate variables, no funky
%>%notation
- build code blocks without intermediate variables, no funky
- Strong, static typing
- Multiple access APIs
- Properties:
df.agedf.filter { age > 18 } - Accessors:
df[age]df.filter { age() > 18 } - Strings:
df["age"]df.filter { "age"<Int>() > 18 }
- Properties:
- Cells can contain classes/objects, and use their properties & methods
- Native language functions, rather than re-implementing in the API
-
{ name.upper() }rather than pandas:name.str.upper()
-
- Experiment and build in Jupyter, execute in compiled code
- Easy 2-way interop with collections of classes
.toListOf<MyClass>()
What can we do with a dataframe?
A lot. Almost any kind of data comprehension or manipulation
- sort, filter, append rows
- summarize: count, sum, average, etc
- data editing or calculating, in-place or new columns
- data cleansing – replacing nulls/NAs/missing
- categorizing data or records (enum, classify, factor, etc)
- join with other dataframes, matching by column(s)
- pivot (rearrange rows and columns)
- prepare data for plotting or visualization
- and a lot more
Some of this sounds awfully familiar...
We already have many tools capable of performing these tasks
- Excel
- SQL
- Tableau
- traditional E-T-L tools
- E-L-T, Airflow, Stitch, dbt...
- Kotlin collections
So why add something new to this mix?
Data access

No database access? No SQL? Get outta here with this trash...

- Sure, pandas supports SQL... but only SQL strings, or table access
- dataframe: choose from many ORMs for db access & object creation
- jooQ, ktorm, Exposed, SQLDelight, Spring – all generate typesafe query code
- from Iterable QuerySet, or collection, or map, just
.toDataFrame() - modularity extends to Apache POI (Excel), OpenCSV, Kotlin-CSV, etc
Use case: transitioning away from SQL & Excel
- Previously, an almost entirely manual Excel process
- tedious, time-consuming, error-prone, redundant
- copy/paste, sorting, filtering, formula coverage – all manual
- no JSON or XML output, no CSV customization
- Intermediate phase: convert to a database-heavy process
- primary RDBMS server locked down by IT, required a secondary server
- lots of complex views, each with multiple CTE's
- messy, difficult maintenance, maze of processes, no source control or tests
- launched via IDE, still no file output support (JSON, XML, CSV)
- Best: logic & formatting w/ Kotlin & dataframe + web front-end
- still use database for persistence, processes start with basic queries
- dataframe works with arrays/lists & objects, many SQL sources don't
- dataframe can replicate, and improve on, previous SQL views & procedures
- table joins, filters & "group by" aggregations
- pivoting (much easier with dataframe)
- string formatting, date conversion (embed functions in classes)
- simpler, less verbose syntax overall
- procedural branching (if/else, when)
- debugging/walkthrough – halt and view state of data – plus testing
- easy to embed process behind HTTP endpoint, runnable via web front-end
- Alternatives: enterprise-scale marketing automation platforms
- IBM Unica
- Adobe Marketing Cloud
- SAS
- Teradata Aprimo
- etc
Use case: transitioning away from SQL & Excel
Goal: Build customized marketing campaigns for casino patrons

I was promised code, let's see some code!

Dataframe is great... but a work in progress
Project is very much still in beta (alpha?) mode
- Incomplete documentation, no dplyr-like "cheat sheet"
- No official project roadmap, upcoming features unknown
- Mature tools have wider scope of functionality
- range lookups (pandas
merge_asof, SQL join with>&<, ExcelVLOOKUP) - SQL window functions (i.e. determining rank within a group)
- binning (for histograms), sampling
- range lookups (pandas
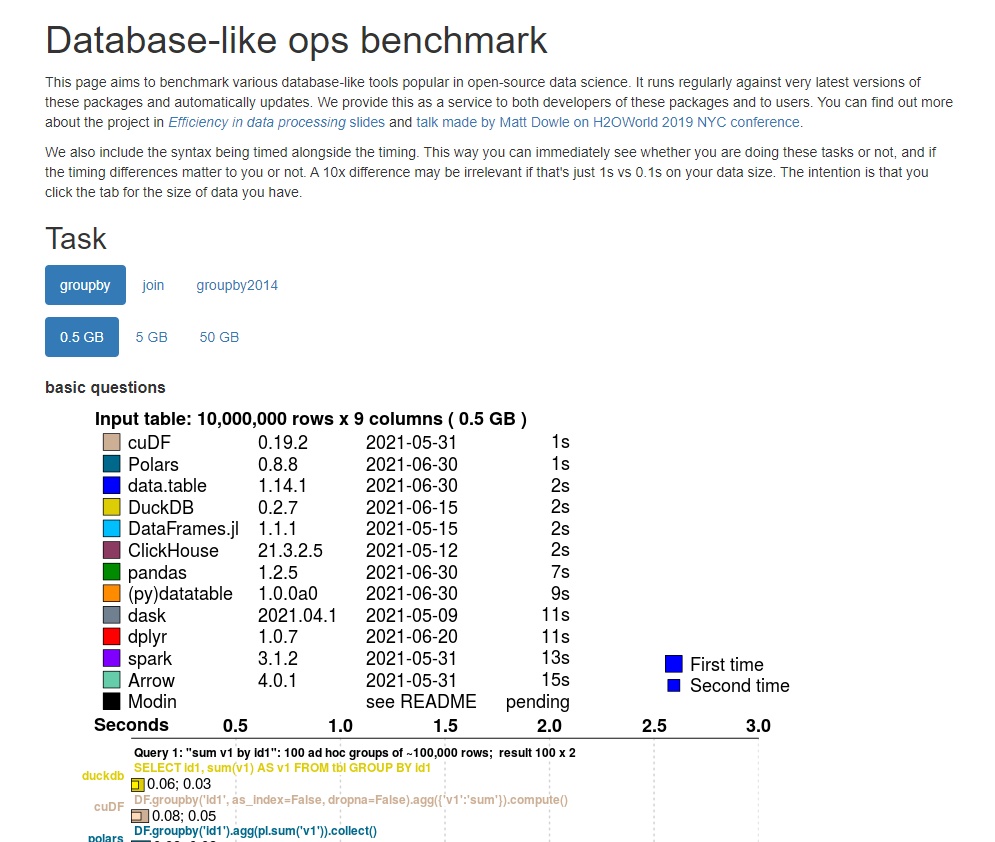
Speed and data capacity trail other projects significantly
- JVM Vector API is still in preview
- High-performance libraries built many core functions in native C
- "boxed" values (rather than primitives) are not memory-efficient
- utilize GPU?
Wishlist
As dataframe approaches beta/release
- Embrace the biggest advantage, the API, and build out functionality
- Build upon JVM Vector API for next LTS release (v21)
- Embrace next-gen projects
-
Apache Arrow – zero-copy data access

- Apache Parquet – column-oriented file format
- DuckDB – in-process, vectorized OLAP DB engine
- all have Java APIs – could dataframe offload implementations?
-
Apache Arrow – zero-copy data access
- Marketing – more eyes = more usage = more resources
